Google STT와 PlayChat 연동
related files
- demo2.html, demo2.js, demo2.css
이 페이지에서는 화면에서 AI와 대화를 나누는 예제를 제공합니다. 이와 같이 AIPlayer와 플레이챗을 결합함으로 대화형 AI 서비스를 만들 수 있습니다. 플레이챗(딥브레인 제공)은 봇과 문자 메시지를 통해 대화를 나눌 수 있는 챗봇 서비스입니다.
여기에서 플레이챗은 AIPlayer와 통합되어 있으며, AI는 그 챗봇에서 나오는 문장을 말할 것입니다. 즉, 사용자가 인공지능과 대화를 할 수 있는 것입니다.
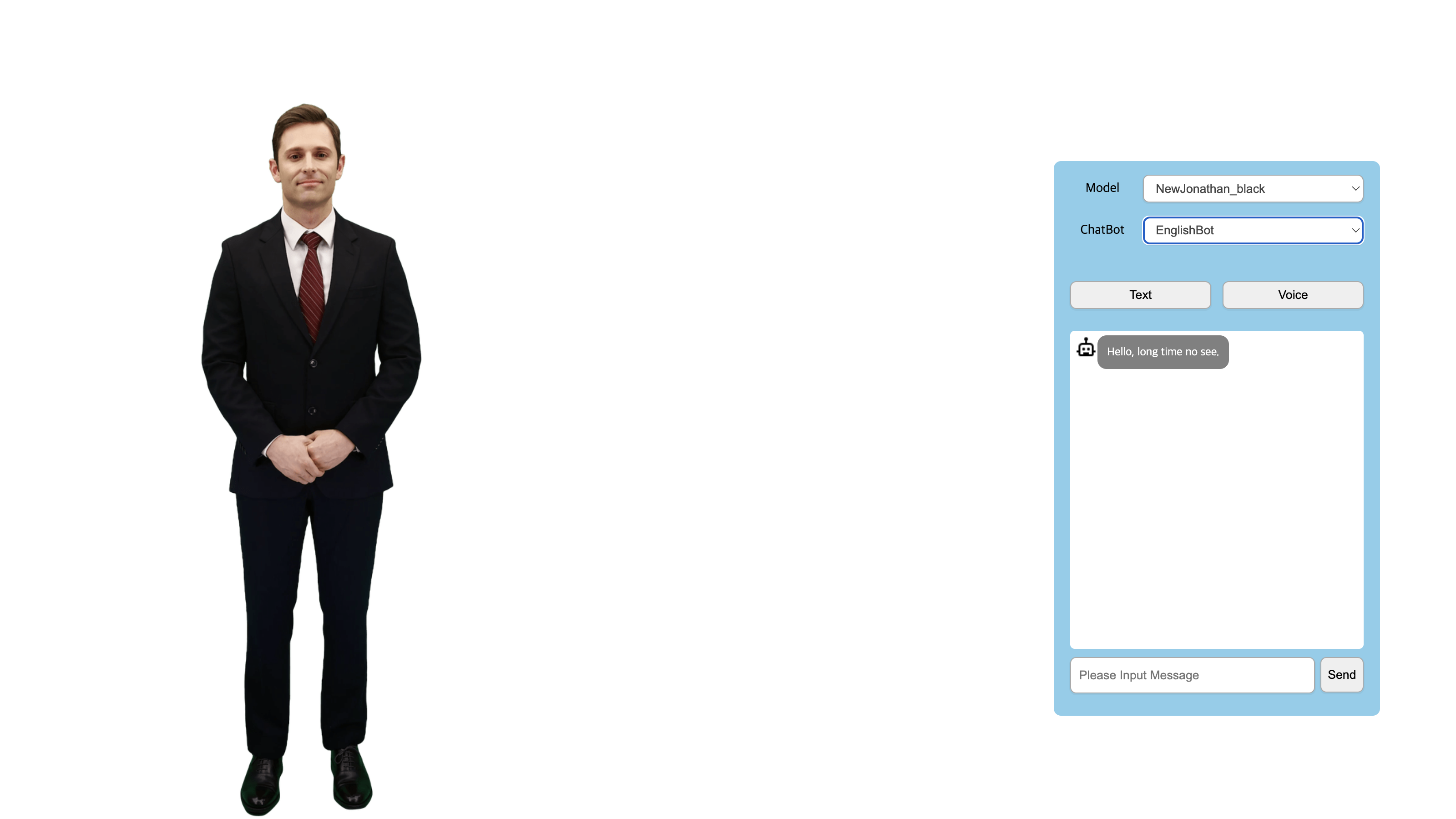
1. Chatbot (Wrapper Class of PlayChat) 설정
1.1. chatbot.js file을 web page에 추가
<script src="https://cdn-aihuman.deepbrainai.io/sdk/web/chatbot.js"></script>
1.2. DeepBrain Chatbot 개체를 생성
const CHATBOT = new DeepbrainChatbot();
1.3. CHATBOT 응답을 위해 콜백을 구현
function initChatBotEvent() {
CHATBOT.onChatbotMessage = async (json) => {
// ...
await speak(json?.text); // Making CHATBOT speak to AI about the text it receives
};
CHATBOT.onChatbotStateChanged = (json) => {
if (json?.kind == "postUserInput" && json?.state == "complete") {
onUserInput = true;
}
if (json?.kind == "dialog" && json?.state == "complete") {
// ...
onUserInput = false;
onEnd = true;
}
};
CHATBOT.onChatbotError = (json) => {
showPop("IChatbot Error", `[${err.errorCode}] ${err.error}\n${err.description}\n${err.detail || ""}`);
};
}
1.4. CHATBOT 시작하기
function startChat(obj) {
// ...
CHATBOT.init({ ChatbotSettings: { botId: DATA.botId } });
}
1.5. Chatbot에 메세지 보내기
function sendMessage(message) {
//...
await refreshTokenIFExpired();
CHATBOT.send({ cmd: "postUserInput", args: { text: message } });
}
2. Google STT 셋업
- 이 예에서는 AI와 대화할 때 음성 인식(Google STT)이 사용됩니다. STT는 내부의 웹 소켓을 통해 서버와 통신합니다. 설정은 다음과 같습니다.
2.1. Server socket source
const speech = require("@google-cloud/speech");
const speechClient = new speech.SpeechClient(); // Creates a client
// ...
/*****
* google-stt start
* ******/
let recognizeStream = null;
// =========================== GOOGLE CLOUD SETTINGS ================================ //
// The encoding of the audio file, e.g. 'LINEAR16'
// The sample rate of the audio file in hertz, e.g. 16000
// The BCP-47 language code to use, e.g. 'en-US'
const encoding = "LINEAR16";
const sampleRateHertz = 16000;
let languageCode = "en-US"; //en-US, ko-KR
const request = {
config: {
encoding: encoding,
sampleRateHertz: sampleRateHertz,
languageCode: languageCode,
profanityFilter: false,
enableWordTimeOffsets: true,
},
interimResults: true, // If you want interim results, set this to true
};
socket.on("startGoogleCloudStream", function (data) {
// start recognition
if (data.phrases && data.phrases.length > 0) request.config.speechContexts = [{ phrases: data.phrases }];
else delete request.config.speechContexts;
startRecognitionStream(this, data);
});
socket.on("setRecognizeLanguage", function (language) {
// set the lang
languageCode = language;
request.config.languageCode = languageCode;
});
socket.on("endGoogleCloudStream", function (data) {
// end recognition
stopRecognitionStream();
});
socket.on("binaryData", function (data) {
//log binary data
if (recognizeStream !== null) {
recognizeStream.write(data);
}
});
function startRecognitionStream(socket, data) {
recognizeStream = speechClient
.streamingRecognize(request)
.on("error", console.error)
.on("data", (data) => {
socket.emit("speechData", data); // send to client
// if end of speaking, let's restart stream
// this is a small hack. After 65 seconds of silence, the stream will still throw an error for speech length limit
if (data.results[0] && data.results[0].isFinal) {
stopRecognitionStream();
startRecognitionStream(socket);
}
});
}
function stopRecognitionStream() {
if (recognizeStream) {
recognizeStream.end();
}
recognizeStream = null;
}
/*****
* google-stt end
* ******/
2.2. Client socket source
- Google STT socket client setup
// ...
const socket = io("socket server address",{ transports: ["websocket"] });
// ...
function initSocketEvent() {
socket.on("connect", function (data) {});
socket.on("speechData", function (data) {
const dataFinal = undefined || data.results[0].isFinal;
if (dataFinal === false) {
if (removeLastSentence) googleSttText = "";
removeLastSentence = true;
} else if (dataFinal === true && isFinal) {
isFinal = false;
googleSttText = "";
googleSttText = capitalize(addTimeSettingsFinal(data));
removeLastSentence = false;
stopRecording(true);
}
});
}
- 음성인식의 시작, 중지
function startRecording(_stringArray) {
// start recognition
socket.emit("startGoogleCloudStream", { phrases: _stringArray || [] }); //init socket Google Speech Connection
streamStreaming = true;
// Web API init
context = new (window.AudioContext || window.webkitAudioContext)({
// if Non-interactive, use 'playback' or 'balanced' // https://developer.mozilla.org/en-US/docs/Web/API/AudioContextLatencyCategory
latencyHint: "interactive",
});
processor = context.createScriptProcessor(bufferSize, 1, 1);
processor.connect(context.destination);
context.resume();
const handleSuccess = function (stream) {
globalStream = stream;
input = context.createMediaStreamSource(stream);
input.connect(processor);
processor.onaudioprocess = function (e) {
microphoneProcess(e);
};
};
// Older browsers might not implement mediaDevices at all, so we set an empty object first
if (navigator.mediaDevices === undefined) navigator.mediaDevices = {};
// Some browsers partially implement mediaDevices. We can't just assign an object
// with getUserMedia as it would overwrite existing properties.
// Here, we will just add the getUserMedia property if it's missing.
if (navigator.mediaDevices.getUserMedia === undefined) {
navigator.mediaDevices.getUserMedia = function (constraints) {
// First get ahold of the legacy getUserMedia, if present
const getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia;
// Some browsers just don't implement it - return a rejected promise with an error
// to keep a consistent interface
if (!getUserMedia) return Promise.reject(new Error("getUserMedia is not implemented in this browser"));
// Otherwise, wrap the call to the old navigator.getUserMedia with a Promise
return new Promise(function (resolve, reject) {
getUserMedia.call(navigator, constraints, resolve, reject);
});
};
}
navigator.mediaDevices.getUserMedia(constraints)
.then(handleSuccess)
.catch(function (err) {
console.log("media devices err", err);
});
}
function stopRecording(hasUserInput) {
// hasUserInput is true: run userInput, false: end recognition
if (!streamStreaming) return;
streamStreaming = false;
// end recognition
if (socket) socket.emit("endGoogleCloudStream", "");
const track = globalStream?.getTracks() ? globalStream.getTracks()[0] : false;
if (track) track.stop();
if (input && processor) input.disconnect(processor);
if (processor && context.destination) processor.disconnect(context.destination);
if (context) {
context.close().then(function () {
input = null;
processor = null;
context = null;
});
}
const userVoiceInput = googleSttText?.trim();
// ...
if (hasUserInput) sendMessage(userVoiceInput);
else {
// ...
}
}
function microphoneProcess(e) {
const left = e.inputBuffer.getChannelData(0);
const left16 = downsampleBuffer(left, 44100, 16000);
socket.emit("binaryData", left16);
}
function capitalize(s) {
if (s.length < 1) return s;
return s.charAt(0).toUpperCase() + s.slice(1);
}
function downsampleBuffer(buffer, sampleRate, outSampleRate) {
if (outSampleRate == sampleRate) return buffer;
if (outSampleRate > sampleRate) throw "downsampling rate show be smaller than original sample rate";
const sampleRateRatio = sampleRate / outSampleRate;
const newLength = Math.round(buffer.length / sampleRateRatio);
const result = new Int16Array(newLength);
let offsetResult = 0;
let offsetBuffer = 0;
while (offsetResult < result.length) {
let nextOffsetBuffer = Math.round((offsetResult + 1) * sampleRateRatio);
let accum = 0,
count = 0;
for (let i = offsetBuffer; i < nextOffsetBuffer && i < buffer.length; i++) {
accum += buffer[i];
count++;
}
result[offsetResult] = Math.min(1, accum / count) * 0x7fff;
offsetResult++;
offsetBuffer = nextOffsetBuffer;
}
return result.buffer;
}
function addTimeSettingsFinal(speechData) {
return speechData.results[0].alternatives[0].transcript;
}