Lipsync와 TTS 연동
related files
- 5.uLipsync & TTS.scene
이번 데모는 외부 3D모델 + uLipsync + TTS를 연동한 Lipsync AI 서비스의 예제입니다. 사용자로부터 문장을 입력 받아 발화(Lipsync)까지의 과정이 간단하게 구현되어 있습니다. 해당 demo scene을 실행하면 유니티 사용자들에게 익숙한 Unity chan 캐릭터를 볼 수 있습니다.
Built-in, URP 지원
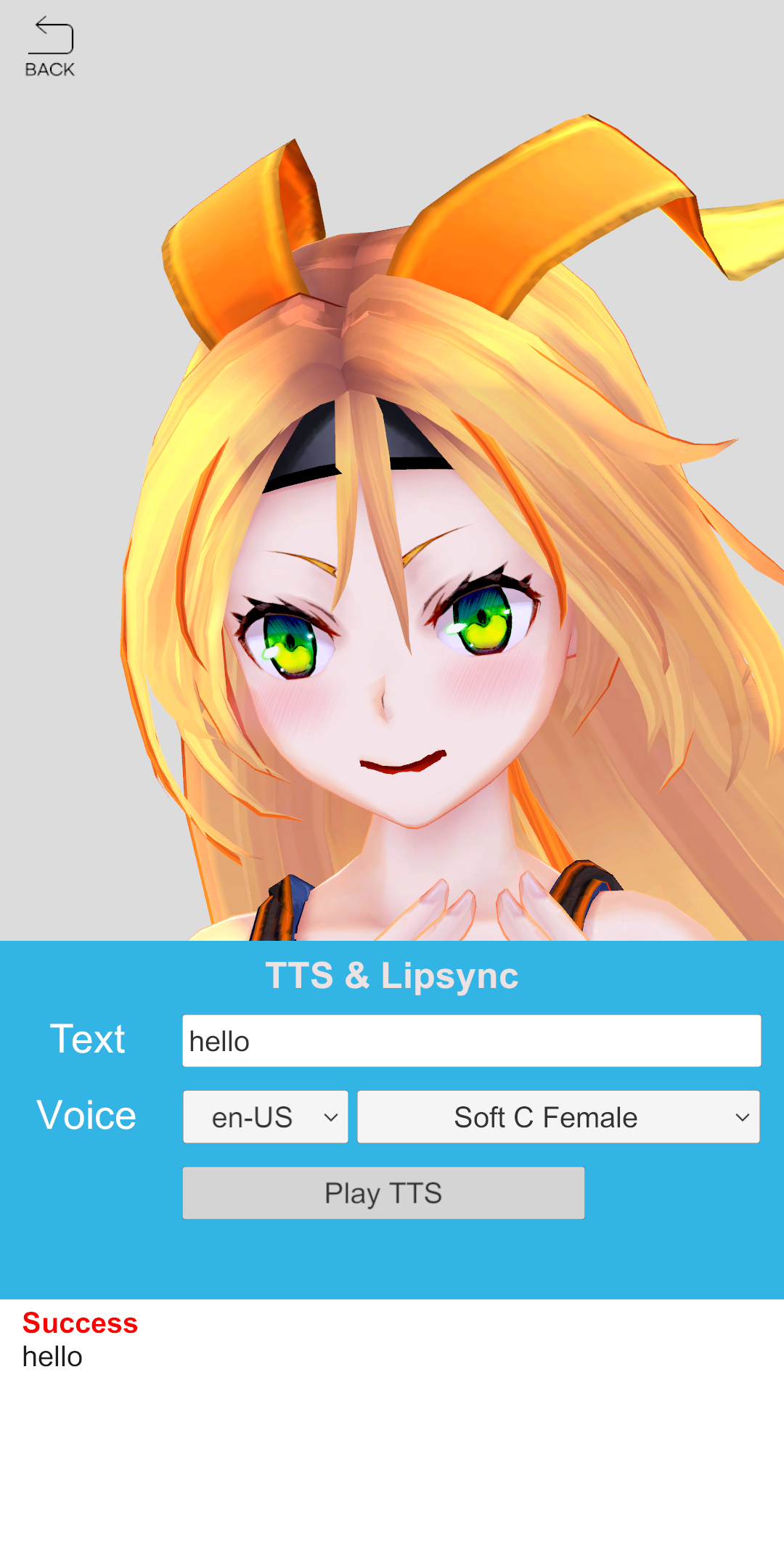
3D모델 + uLipsync + TTS 함께 사용하기
해당 Demo에서 Lipsync AI 서비스를 사용해 보려면, 아래와 같이 준비 과정이 필요합니다.
- 3D모델 준비하기: 데모에 포함되어 있음 (Unity chan)
- uLipsync 준비하기: 데모에 포함되어 있음 (https://github.com/hecomi/uLipSync)
팁
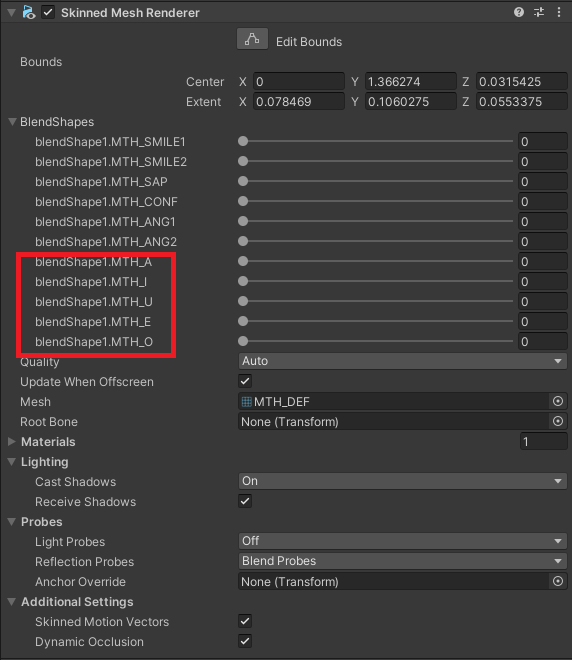
3D모델은 아래와 같이 립싱크에 필요한 BlendShapes 구성이 필요합니다. (Unity Chan 캐릭터의 발음 입모양 관련 blendshapes)
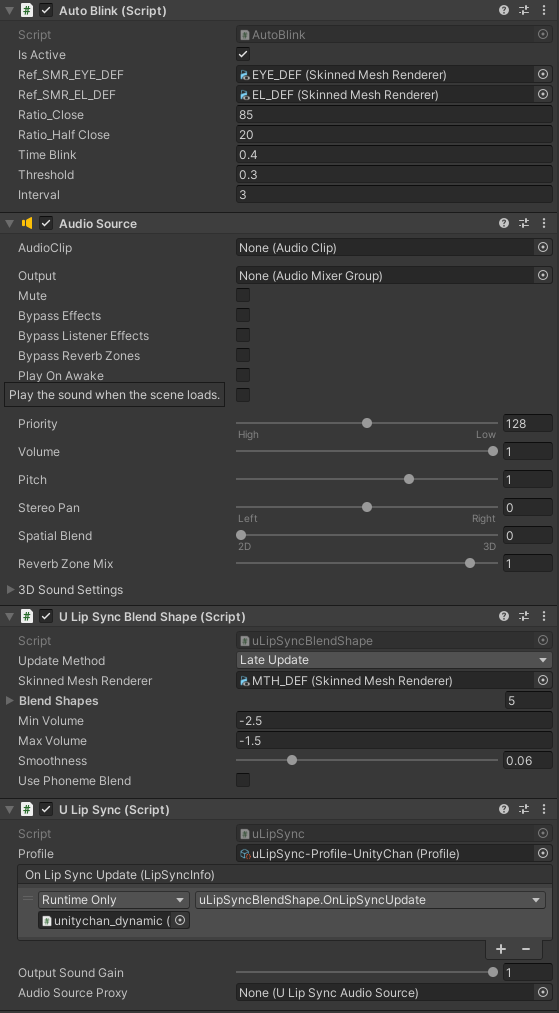
발화(Lipsync)를 위해서는 아래와 같은 컴포넌트 구성이 필요합니다.
- Lipsync : uLipSync, uLipSyncBlendShape
- 음성 플레이 : AudioSource
- 눈 깜박임 : AutoBlink (사용하려는 3D모델에 눈 깜박임 관련 BlendShapes이 구성되어 있을 경우)
이 데모는 음성 합성을 통해 전달 받은 AudioClip을 이용하여 립싱크를 구현하는 것이 주목적입니다. 데모의 Play TTS 버튼의 클릭 이벤트 함수인 OnClickSpeech의 작성을 통해 해당 내용을 구현하였습니다. AudioSource의 clip 항목에 전달 받은 AudioClip을 설정하고 AudioSource.Play()을 호출하면 립싱크가 자동으로 플레이됩니다.
AudioClip을 요청한 후 전달 받은 AudioClip을 설정하고 플레이합니다
- DemoTTSLipsync.cs
public void OnClickSpeech()
{
if (string.IsNullOrEmpty(_inputSpeech.text))
return;
_resultText.text = "<b><color=#0000ff>Synthesizing...</color></b>";
// 음성 ID를 가져온다.
string voiceID = _customVoiceList[_dropdownVoice.value].ID;
// 합성 할 텍스트와 음성 ID를 전달인자로 AudioClip을 요청한다.
AIAPI.Instance.GetAudioClip("chan", _inputSpeech.text, voiceID, (aiName, clipset, aiError, audioClip) =>
{
if (aiError != null)
{
_resultText.text = "<b><color=#ff0000>>Failure</color></b>\n" + aiError.Description;
}
else
{
_audioSource.clip = audioClip;
_audioSource.Play();
_resultText.text = "<b><color=#ff0000>Success</color></b>\n" + clipset.SpeechText;
}
});
}
위 설명은 중략된 부분이 많습니다. 더 자세한 내용은 데모의 Hierarchy 구성과 캐릭터 리소스 설정을 참고 바랍니다.